




Způsoby implementace AI ve firmách, funkce AI nad firemním know-how a s tím související aspekty zabezpečení firemních dat

CEO, Kontis s.r.o.
45 minut čtení

Shrnutí: Jak funguje AI na bázi LLM, jakými způsoby lze toto AI do firmy implementovat, jak těmito způsoby implementované AI funguje a na co se zaměřit, aby firemní implementace AI byla efektivní a dávala smysl, to vše je předmětem tohoto článku. Implementace AI nad firemním know-how přináší mimo jiné nový pohled na zabezpečení firemních dat, stávající firemní bezpečnostní pravidla pravděpodobně nebudou pokrývat situaci po implementaci AI, k tomu článek také popisuje řešení.
Abstrakt
Implementace umělé inteligence (AI) na bázi velkých jazykových modelů (LLM) ve firemním prostředí představuje příležitost, jak zvýšit produktivitu zaměstnanců, zefektivnit jejich práci s informacemi, zlepšit využívání firemního know-how zaměstnanci, zákazníky či partnery, částečně či zcela automatizovat a robotizovat vybrané firemní procesy. Zároveň tato implementace přináší nová rizika v oblasti zabezpečení firemního know-how a kvality výstupů, na jejichž základě dochází k rozhodování uvnitř i vně firmy.
Pro správnou implementaci a používání AI nad firemním know-how je potřeba rámcově chápat funkci LLM (velkých jazykových modelů) a s nimi souvisejících technologií. To umožní lépe např. pochopit hranice, kde je efektivní AI používat a kde ne, co to jsou halucinace, jak LLM s firemním know-how pracuje, jak se rozhoduje. To vše je vysvětlené v kapitole Fungování AI na bázi LLM, související technologie jsou pak vysvětleny v Metodách implementace AI, zejména v podkapitole RAG Architektura. Bez tohoto pochopení podstaty AI hrozí, že výsledkem implementace AI ve firmě nejen nebudou výše jmenované přínosy, ale tato implementace AI kromě finanční ztráty může i způsobit těžko opravitelné škody uvnitř firmy i směrem k zákazníkům.
Existují 3 základní metody implementace AI na bázi LLM nad firemním know-how:
- Využívání veřejných AI nástrojů jako např. ChatGPT, Copilot, Google Gemini: To je rychlé a levné řešení bez nutnosti implementace. Není však napojeno na interní know-how firmy, což omezuje jeho využitelnost. Při práci s interními daty vzniká riziko jejich úniku mimo firmu.
- Trénink vlastního LLM nad firemními daty: Technicky komplexní a finančně náročný přístup. Přináší vysokou míru kontroly nad daty, ale má zásadní nevýhody, zejména obtížnou aktualizaci znalostí, riziko nepřesností a nemožnost efektivně řídit přístupová práva k informacím uvnitř firmy.
- RAG (Retrieval-Augmented Generation) architektura: Moderní, doporučená a v současnosti nejrozšířenější metoda. Kombinuje výhody obou předchozích přístupů s potlačením jejich nevýhod:
- LLM pracuje s aktuálním firemním know-how bez nutnosti tréninku modelu.
- Odpovědi jsou podloženy konkrétními zdroji pro eliminaci halucinací.
- Lze efektivně řídit přístupová práva k firemnímu know-how.
Jednotlivé metody implementací AI jsou vysvětlené v kapitole Metody implementace AI, zde jednoduchá srovnávací tabulka metod implementace:
| Kritérium | Veřejné AI nástroje | Trénink interního LLM | RAG architektura |
|---|---|---|---|
| Náklady | nízké | vysoké | střední |
| Bezpečnost | nízká | vysoká navenek, nízká uvnitř firmy | vysoká |
| Přesnost | nízká | střední | vysoká |
Je důležité zmínit, že pro úspěšnou implementaci AI do firmy jakoukoliv výše jmenovanou metodou je nutné vedle zvládnutí technické stránky implementace také zapojit zaměstnance do procesu implementace a následného využívání AI. Es nutné řídit tuto změnu ve firmě dle známých pravidel tzv. change managementu se zaměřením na lidskou stránku, komunikaci, vzdělávání a vedení. Tyto aspekty tento článek neřeší.
Aby tento článek nebyl jen teoretickým výkladem, v poslední kapitole Ukázka implementace AI s RAG v platformě iTutor je popsána v konkrétní softwarové platformě praktická implementace AI na bázi LLM nad firemními daty s Agentickou RAG architekturou.
Fungování AI na bázi LLM
V článku se zabýváme implementacemi, kdy AI pracuje s firemním know-how a pomocí Chatbotů, Agentů a dalších prostředků pomáhá zaměstnancům plnit efektivněji jejich pracovní úkoly, či dokonce AI část těchto úkolů přejímá a vykonává je sama. Pro určení, jakou metodu takovéto implementace AI zvolit a jaká přijmout nová pravidla zabezpečení dat, je dobré porozumět konkrétním metodám implementace AI a rámcově pochopit fungování AI nad firemním know-how.
V této první kapitole si velmi zjednodušeně vysvětlíme fungování AI nad firemním know-how, které je uložené ve formě textů, či v podkladech převoditelných na texty, jako je např. zvuk, video, či obrázky. Takovéto texty tvořící firemní know-how jsou obvykle uloženy na mnoha místech, např. ve firemním systému pro správu dokumentů, na discích, v intranetu firmy i na jejích internetových stránkách, ve firemních databázích, diskusních fórech, mailech, CRM či ERP systémech apod.
Pokud víte, co to je LLM, na jakém principu pracuje, jak se učí, jak odpovídá na prompt, co to je embedding, jak se liší embeddingy pro RAG od embeddingů uvnitř LLM, či jak s embeddingy pracuje vektorová databáze, může zbytek této kapitoly přeskočit a pokračovat v druhé kapitole Metody implementace AI. Na koho bude působit tato první kapitola příliš technicky a podrobně, může ji také přeskočit a pokračovat v druhé kapitole. Odtud se sem v případě potřeby může vracet ke konkrétním pojmům, když mu nějaký použitý termín v druhé kapitole nebude jasný a rád by se o něm něco dozvěděl blíže.
LLM
„Mozkem“ AI pro práci nad firemním know-how je tzv. LLM, Large Language Model, česky Velký Jazykový Model. Lze si jej představit jako „někoho“, kdo si přečetl „všechny informace na světě“ (veřejně dostupné texty na internetu), a na základě toho odpovídá na dotazy uživatelů či řeší jejich požadavky vznesené v přirozeném jazyce. Odpovědi LLM jsou opět v přirozeném jazyce.
Tento „mozek“ nepřemýšlí zcela stejně jako lidský mozek, na to víme ještě příliš málo, jak lidský mozek přemýšlí, abychom to dokázali simulovat počítačově. LLM je vybudován nad architekturou zvanou počítačová neuronová siť. Ta je inspirována činností neuronů v mozku. Počítačová neuronová síť se skládá z ohromného množství počítačově reprezentovaných neuronů, každý neuron je simulován jedním reálným číslem. Počítačové neurony jsou umístěných ve vrstvách, každý neuron ve vrstvě je propojený se všemi neurony předchozí vrstvy tak, že se do něj přenáší pomocí vah hodnota z každého propojeného neuronu předchozí vrstvy. Zvážené hodnoty vstupních neuronů se agregují do výsledného čísla, ke kterému se přičte konstanta (bias), a na výsledek se aplikuje aktivační funkce (např. ReLU, Sigmoid nebo Tnav), která do systému vnese nelinearitu. Tak vznikne hodnota (číslo) výstupního neuronu. Znalosti největších LLM jsou tedy reprezentovány architekturou propojení neuronů ve vrstvách a hodnotami stovek miliard až bilionů vah a biasů (biasů je méně než vah, na jeden bias je obvykle tisíc i více vah), kde hodnoty vah a biasů se nastaví při tréninku (učení).
Zjednodušeně, naučené neuronové síti vložíte na vstup reprezentovaný vstupní vrstvou neuronů nějaká čísla, tolik čísel, kolik má vstupní vrstva neuronů. Tato čísla se pomocí nastavených vah a biasů postupně přenáší do neuronů v dalších vrstvách, až se objeví jako nějaká jiná čísla v neuronech na výstupní vrstvě sítě. Výstup neuronové sítě je opět tolik čísel, kolik má výstupní vrstva neuronů. Když se neuronová síť učí, dávají se jí na vstup vzorky vstupních čísel, a ukazují se jí vždy pro každý takový vstupní vzorek, jaký vzorek výstupních čísel je očekáván na výstupu. Neuronová sít si ve fázi učení upravuje své váhy a bias pomocí procesu, který se nazývá backpropagation tak, aby se pro zadané vstupní vzorky její výstupní vzorky co nejvíce podobaly očekávaným výstupním vzorkům.
LLM nepracuje s čísly, ale s texty, výše popsaný princip je nicméně podobný. Ve fázi učení se vezmou „všechny dostupné texty z internetu“. Což samo o sobě je složitý proces, zahrnující vyfiltrování těchto dat,Rainbow textů z internetu vlastně popojíždíme oknem, které mění šířku od jednoho slova až po maximálně podporovaný počet slov na vstupu LLM, čemuž se říká velikost kontextového okna LLM. Např. u textu „Kočka leze dírou, pes oknem“ se na vstup LLM pošle v prvním okně „Kočka“ a ukáže se, že na výstupu je očekávané slovo „leze“. Pak se na vstup LLM pošle rozšířené okno „Kočka leze“ a ukáže se, že na výstupu očekáváme slovo „dírou“, atd., až se na konec pošle „Kočka leze dírou, pes“ a ukáže se očekávané „oknem“. Kdyby velikost kontextového okna LLM byla jen 3 slova, reálně je o mnoho větší a obvykle pojme 150 až 300 stran textu, po dosažení 3 slov na vstupu („Kočka leze dírou“) by se jako další vstup LLM poslalo posunuté okno „leze dírou, pes“ a takto by se s oknem o velikosti 3 slova projelo celým vstupním textem. LLM si ve fázi učení pomocí backpropagation nastaví ze všech poslaných textů na vstup až biliony svých vah, a tak se v jeho váhách zafixují nejen syntaktická pravidla přirozeného jazyka, ale i znalosti ukryté v zaslaných textech.
Natrénovaný LLM poté řeší požadavky či dotazy uživatelů, nebo agentů AI tak, že textově zformulované požadavky či dotazy, které svou délkou nepřekročí velikost kontextového okna LLM, se předají na vstup LLM. Takto naformulovaný text předávaný LLM jako vstup se nazývá prompt. LLM ze vstupního promptu „vypočte“ výše popsaným průchodem všemi vrstvami neuronů s nastavenými vahami z doby učení první slovo výstupu, které bude v jeho odpovědi. Toto vypočtené slovo LLM přidá na konec textu vstupního promptu, a takto upravený prompt pošle opět sám na sebe jako vstup. Tak LLM vypočte druhé slovo své odpovědi. To by se mohlo opakovat do nekonečna, proto se LLM dokáže v určité chvíli „rozhodnout, že to už stačí“ a jím takto vygenerovanou odpověď s konečným počtem slov předá tazateli.
Takto velmi zjednodušeně vysvětlená funkce LLM stačí pro pochopení, jak přistupovat k odpovědím, které nám dává LLM. Tzn. že něco, čemu se říká halucinace, jinými slovy logická a srozumitelná odpověď LLM obsahující po faktické stránce naprosté či částečné nesmysly, nejsou chybou LLM, kterou půjde nějak zcela opravit, ale podstatou fungování LLM. Neuronová síť si ve fázi učení na základě vstupních dat nastavila až biliony svých vah a biasů mezi neurony. Odpověď na dotaz uživatele je pak jen matematický postup, jak se na základě těchto vah, biasů a struktury propojení vrstev neuronů spočte pravděpodobná odpověď. Že pravděpodobná odpověď nemusí být pravdivá, je asi jasné. Riziko halucinací neklesne na nulu z podstaty fungování LLM; nástroje pro jejich potlačování, např. trénink na kvalitnějších, ověřenějších datech prošlých náročným procesem kurace, používání lidské zpětné vazby při tréninku (RLHF), či řízení pravděpodobnosti odpovědi halucinacím nikdy nezabrání zcela, jen je minimalizuje.
Pro pochopení dvou ze tří základních metod implementace AI ve firmě nad firemním know-how, popisovaných v následující kapitole Metody implementace AI. Existuje další, nejpoužívanější metoda implementace AI, využívající technologii RAG, která nejlépe řeší jak výše zmíněné halucinace, tak zabezpečení firemního know-how, ke kterému se LLM dostává. Kvůli této metodě si ještě zjednalezujeme říct něco o převodu textů na čísla a pár informací navíc.
Embeddingy
LLM je neuronová síť, ta pracuje s čísly, ne s texty. Je dobré rámcově chápat, jak se vstupní texty posílané do LLM v promptu převou na čísla, a jak se z číselného výstupu neuronové sítě LLM zpětně udělá slovo. Pro technologii RAG je převod textů na čísla zásadní i z jiného důvodu, kvůli vyhledávání podkladů pro odpověď LLM.
Metoda převodu textu na čísla je postavena na něčem, čemu se říká embedding. Embedding, do češtiny obvykle nepřekládaný výraz, je číselné vyjádření kontextového významu slova. Každé slovo jde převést na embedding, 2 slova sobě kontextově významově blízká mají i sobě blízké embeddingy. Takováto číselná reprezentace významu slova nejde vyjádřit jedním číslem, např. že by stůl měl číslo (embedding) 4 a židle 6. To jsou si sice docela blízká čísla, protože i stůl a židle jsou si něčím významově blízké, ale při takovémto způsobu číslování slov bychom brzy skončili, že už nejde vyjádřit významová blízkost a vzdálenost různých slov, aniž by se to vzájemně číselně nevylučovalo. Embedding proro není jedno číslo, ale vektor čísel, bývá to někdy až více tisíců čísel v jednom embeddingu. V takovémto mnoha-číselném vektorovém prostoru lze matematicky např. pomocí Kosinové podobnosti či Eukleidovské vzdálenosti určovat blízkost/vzdálenost jednotlivých embeddingů, vlastně bodů v tomto prostoru, reprezentujíc kontextový význam jednotlivých slov. Zároveň do takovéto vektorové reprezentace kontextového významu slova již lze „zakódovat“ význam všech slov tak, aby jejich blízkost vycházela „správně“. Embeddingy lze vytvářet nejen ze slov, ale i z celých textů, embedding takového textu má v sobě zakódovaný význam celého textu.
Něco navíc
Pro ty, kteří mají pocit, že zde zjednodušujeme příliš, a že zde chybí vysvětlení řady věcí, pár stručných poznámek na závěr.
- Embeddingy se ve skutečnosti nedělají ze slov, ale z tzv. tokenů. Token může být i jen část slova. LLM si pak dokáže poradit i se slovy, které nikdy neviděl, může lépe zvládnut gramatiku složitějších jazyků jako je např. čeština, a lze vytvářet relativně malé slovníky tokenů, kolem 100 000 tokenů, kterými lze pokrýt všechna slova přirozeného jazyka. Těch je samozřejmě mnohem více, např. v češtině je slov kolem 250 000, a to jen v jejich základní podobě, díky skloňování, časování, odborným a slangovým výrazům to jde do milionů. Metody, jak dělat tokeny jsou různé, např. slovo „nejobhospodařovanější“ by se mohlo rozpadnout na tokeny „nej“, „ob“, „hospoda“, „řov“, „an“ a „ější“. Jak je vidět, z těchto tokenů a dalších jim podobných půjde složit mnoho jiných českých slov, aniž tato slova musí být ve slovníku.
- Embedding z tokenu se vypočítává pomocí neuronové sítě. LLM v sobě má slovník, technicky je to první vrstva jeho neuronové sítě. Má-li tento slovník např. 100 000 tokenů a embedding obsahuje 16 384 dimenzí (čísel), jedají se o matici 100 000 x 16 384 čísel, kde každý řádek reprezentuje embedding konkrétního tokenu ze slovníku. Na začátku učení je tato matice naplněna náhodnými čísly, během fáze učení se zpřesňují pomocí backpropagation nejen váhy neuronové sítě LLM, ale i tato čísla, reprezentující hodnoty tokenů.
- Vstupem do neuronové sítě LLM není řada čísel, jak bylo vysvětleno pro obecnou neuronovou síť výše, ale matice, kde na každém řádku je embedding jednoho tokenu ze vstupního textu. Navíc je zde přidáno poziční kódování, aby neuronová síť mohla pochopit, že to není jen „hromada“ slov (tokenů), ale že ty tokeny mají své pořadí a vztah k okolním tokenům.
- Embeddingy nejde snadno převádět zpětně na slova. U LLM se to zjednodušeně dělá, tak, že na výstupní vrstvě neuronové sítě je tolik neuronů, kolik je slov (tokenů) ve slovníku. Hodnota každého suchého neuronu se přepočte na pravděpodobnost, s jakou se má slovo ze slovníku reprezentované tímto neuronem objevit v textovém výstupu LLM. Jako finální slovo se zvolí buď slovo s nejvyšší pravděpodobností. Při této volbě se ale LLM chová trochu jako robot, odpovědi jsou stabilní ale málo kreativní. Nebo se podle tzv. „teploty“ a náhodného výběru zavede do odpovědí neurčitost, což může vést ke kreativnějším odpovědím, ale také k „blábolení“ či nesmyslům (halucinacím) v odpovědích.
- Pro technologii RAG, která bude vysvětlena ve druhé kapitole, se používají trochu jiné embeddingy. Tyto embeddingy mají obvykle menší rozměr než embeddingy uvnitř LLM, např. 1 536 čísel v jednom embeddingu. Je to proto, že se musí ukládat do vektorové databáze a pak v ní rychle vyhledávat embeddingy dle blízkosti. Vektorová databáze je specializovaný typ databáze pro ukládání a správu dat ve formě číselných polí, tzv. vektorů. Na rozdíl od tradičních databází, které hledají přesnou shodu (např. jméno nebo ID), vektorová databáze umí vyhledávat podle podobnosti významu (blízkosti embeddingů). Embeddingy pro RAG se vytváří obvykle pomocí specializované neuronové sítě. Pro RAG se vyrábí embeddingy z ucelených odstavců textu, ne pouze z jednotlivých slov (tokenů). Tato specializovaná neuronová síť interně vyrobí embeddingy se všech slov (tokenů) v textu, a ve výsledku je shlukne (tzv. pooling) do jediného embeddingu, který obsahuje význam celého textu.
Metody implementace AI
Existuje více metod, jak implementovat AI zpracovávající firemní know-how s pomocí LLM. Zde popíšeme 3 základní způsoby těchto implementací. Metody jsou zde popisovány z technického a bezpečnostního pohledu. Alespoň v úvodu je potřeba zmínit lidský faktor, který se nesmí zanedbat při jakékoliv implementaci AI. Implementace AI přináší často změnu firemních procesů, kultury, je třeba překonat strach zaměstnanců z nahrazení, což je při implementaci AI často větší překážka než technologie samotná. Je nutné správně aplikovat change management, vysvětlit důvody zavedení, spojit implementaci se vzdělávacím procesem, připravit pilotní projekt, vybrat AI ambasadory a udělat řady dalších souvisejících věcí. Toto není předmětem článku. Popis, jak pracovat s lidským faktorem při implementaci AI, by vydal na celý článek podobného rozsahu jako je tento technický článek. V případě zájmu čtenářů zařadíme článek o lidském faktoru a odpovídajících postupech při implementaci AI do Kontis Insights v budoucnu.
3 základní metody implementace AI zpracovávající firemní know-how s pomocí LLM:
Využívání hotových nástrojů AI bez napojení na firemní know-how
Jedná se o nástroje jako je jako je ChatGPT, Microsoft Copilot, Google Gemini, Claude, Perplexity AI, a další obdobné nástroje na bázi LLM. Využívání hotových nástrojů AI přináší nulové náklady na vývoj, téměř okamžitý start řešení či nízké náklady na provoz.
Tyto nástroje nejsou samy o sobě propojeny s firemním know-how, použité LLM o firemním know-how „neví nic“. Ve fázi učení se možná odpovídající LLM naučil něco o firmě ze zdrojů na internetu, např. byl trénován i na firemních internetových stránkách či jiných veřejných zdrojích o firmě. Tyto načtené vědomosti byly sloučeny ve vahách LLM s miliardami ostatních vědomostí načtených z internetu, což nutně vede ke generalizaci. LLM na základě požadavku uživatele v promptu může také dospět k tomu, že si nějaké informace o firmě na internetu vyhledá dodatečně a přidá je si je jako další vstup do promptu. K těmto firemním informacím se LLM dokáže dostat pomocí služeb nějakého internetového vyhledávače, takže texty, které dokáže dohledat, jsou podobné jako texty na vstupu v době učení, jen např. aktuálnější. Z interního firemního know-how v nich mnoho nebude.
Takto používané LLM může skvěle pomoci při řešení pracovních úkolů, ke kterým zaměstnanci nepotřebují firemní know-how. Před používáním je dobré proškolit zaměstnance, aby rámcově chápali, jak LLM funguje a jak správně sestavovat prompt pro LLM, aby dostali co nejlepší odpovědi. Viz první kapitola vysvětlující funkci LLM, pokud uživatel nezadá dostatečně obsáhlý prompt dobře vysvětlující požadavek, LLM nemůže poskytnut kvalitní odpověď.
Problém nastává, chce-li zaměstnanec řešit v AI dotazy či požadavky související s firemním know-how. LLM nemá odpověď „zakódovanou“ ve svých vahách, protože nebyl učen nad firemním know-how. Pravděpodobně neodpoví že neví, spíše si začne vymýšlet, tzv. halucinovat. Jste-li např. výrobní firma vyrábějící na výrobních linkách, a zeptáte se takovéhoto LLM „Jak se na lince pro výrobu produktu X upíná produkt do mechanismu linky“, LLM neřekne, že neví, ale sestaví poměrně věrohodnou odpověď na základě toho, co se naučil ve fázi učení z internetu o různých výrobních linkách či upínání výrobků. Konkrétně pro vaši firmu a vaše postupy může odpovědět sice věrohodně, ale zcela nesprávně.
To vede zaměstnance k vkládání dokumentů s firemním know-how do promptu LLM, na jejichž základě má LLM odpovědět. Např. v uvedeném příkladu výrobní firmy uživatel do promptu vloží dotat a firemní dokument s pracovními instrukcemi pro danou výrobní linku, LLM instruuje, aby odpověděl jen na základě informací v přiloženém dokumentu. Obdobně např. manažer přiloží do promptu smlouvu se zákazníkem a zeptá se, zda něco neporušuje konkrétně jím popsanou činností v promptu a pokud ano, jaké z toho plynou sankce.
Problémy s využíváním LLM bez napojení na firemní know-how
Pokud v takovéto implementaci chtějí uživatelé řešit dotazy či požadavky související s firemním know-how:
- Uživatel musí umět nalézt dokumenty se souvisejícím firemním know-how, které přiloží do promptu. Nalézt všechny takové dokumenty a další zdroje informací, které mohou být v e-mailech, chatech, bug-listech, firemním ERP a podobně není snadné. Uživatel často nenalezne vše z firemního know-how s dotazem související.
- I když uživatel nalezne všechny potřebné podklady pro kvalitní odpověď LLM, nemusí se tyto podklady do promptu vejít, viz velikost kontextového okna LLM vysvětlená v první kapitole.
- I když se podklady do kontextového okna vejdou, pokud jsou velké, LLM v nich hůře hledá relevantní části pro odpověď a ztrácí detail z dlouhého textu.
Zabezpečení dat této metody
Při výše popsaném vkládání podkladů k promptu putují mimo firmu celé firemní dokumenty. I když je komunikace s LLM po cestě zabezpečena a dodavatel LLM zaručuje, že nebude na základě těchto dat učit své LLM, či je využívat k čemukoliv jinému než vygenerování odpovědi LLM, v řadě firem toto v odděleních odpovídajících za zabezpečení firemních dat schváleno nebude. Zejména putují-li promptem ven např. smlouvy se zákazníky, viz předchozí příklad, či dokumenty obsahující citlivá data z pohledu GDPR, může to být problematické. Alespoň se zde musí přijmout další opatření pro zabezpečení dat, jako např:
- Proškolení uživatelů, jaké dokumenty mohou vkládat do promptu. S tím je obvykle spojeno zavedení systému klasifikace firemních dokumentů a přiřazení konkrétní klasifikace ke každému dokumentu, aby byli uživatelé schopni rozpoznat, které dokumenty a za jakých podmínek mohou do promptu vkládat.
- Zavedení systémů DLP (Data Loss Prevention), kontrolující odesílaná data z firmy.
- Implementování AI Gateway, která filtruje prompty, anonymizuje data, audituje použití.
Taková opatření nesou další náklady, a 100% zabezpečení úniku firemního know-how mimo firmu zaručit nedokážou. Pokud je toto cílem, je potřeba LLM „uzavřít“ v intranetu firmy, viz další 2 metody. Vlastní obecně naučené LLM lze i v případě této metody uzavřít uvnitř firmy, avšak nedává to ekonomicky ani funkčně velký smysl bez současné implementace RAG architektury. Jaké vlastní obecně naučené LLM lze uzavírat uvnitř firmy a s jakými je to spojeno požadavky, je proto blíže popsáno až v odstavci Zabezpečení dat vně firmy u metody RAG architektura.
Trénink a implementace interního LLM
Na opačném spektru nákladovosti, doby zavedení, ale i zabezpečení proti úniku firemních dat mimo firmu je metoda vyžadující natrénování vlastního modelu LLM nad firemním know-how. Takovéto LLM poté může pracovat zcela uzavřené ve firemním intranetu. Existují 2 způsoby tréninku LLM nad firemním know-how:
Full training
Při Full training se začíná od nuly, LLM nezná ani jedno slovo, nejsou nastaveny jeho váhy. Es potřeba v tréninku použít „celý internet“, nad jehož daty byla provedena v první kapitole popsaná kurace a navíc do vstupních tréninkových dat zařadit firemní data, opět očištěná. Z popisu tréninku LLM v první kapitole je zřejmé, že s tím je spojena vysoká náročnost na technické odborníky, složité vyčištění dat, velmi vysoké náklady na počítačový výkon, pro představu Full training obvykle vyžaduje tisíce GPU hodin, a fáze tréninku trvá dlouho. Na celý proces tréninku je potřeba vyhradit obvykle několik měsíců. Z těchto důvodů je Full training vlastního LLM pro 99 % firem ekonomicky nesmyslný a nedosažitelný. Zásadní problém při tréninku na firemní data je v tom, že firemní know-how není statická věc, naopak se v čase velmi rychle mění. Každá taková změna firemních dat by vyžadovala nové přetrénování LLM, či jeho dotrénování metodou Fine tuning.
Fine tuning
Při Fine tuning se začíná s již nastaveným, tzn. s obecně natrénovaným veřejně dostupným LLM jako je např. Llama či Mistral. Obecně natrénovaný LLM se poté dotrénuje na firemních datech. To je ekonomicky i časově přijatelnější než Full training, ale i s touto metodou je spojena delší doba implementace, náročnost na technické odborníky a vyčištění vstupních firemních dat, či nutnost neustálého dotrénovávání LLM souvisejícího se změnou firemního know-how.
Problémy s tréninkem LLM nad firemním know-how
Full training i Fine tuning s sebou při tréninku nad firemním know-how nesou kritické nevýhody, mezi než např. patří:
- LLM nedokáže v odpovědích uvádět firemní dokumenty, na základě kterých vygeneroval odpověď. Nejde si tedy ověřit správnost odpovědi LLM, což vzhledem k možnému halucinování LLM popsaném výše je vážný problém.
- Při dotrénování hrozí riziko, že při úpravě vah LLM zapomene některé již naučené věci, to se nazývá „katastrofické zapomínání“. Pokud LLM dotrénováváme jen na firemních datech, i když při každém takovém dotrénování vždy použijeme celou množinu aktuálních firemních dat, hrozí že LLM „zapomene“ něco z úvodního Full trainingu nad celým internetem, LLM se stane expertem na firemní know-how, ale přestane zvládat obecné dotazy nebo logické uvažování. Jsou různé metody jak toto korigovat, nicméně poměrně komplikované a náročné.
- Při dotrénování jsou obvykle firemní data v porovnání s daty z Full tréninku velmi „malá“, hrozí že LLM se trénovací příklady naučí "nazpaměť". Výsledkem je, že LLM skvěle odpovídá na data z trénovací sady, ale selhává v reálném provozu při mírně odlišných dotazech.
Zabezpečení dat této metody
Z hlediska zabezpečení firemního know-how, pokud je natrénovaný LLM uzavřen uvnitř firmy v jejím intranetu, je plně zabezpečeno, že firemní know-how se nedostává mimo firmu. Avšak během tréninku LLM nad firemními daty se firemní know-how stalo součástí vnitřních vah LLM, viz první kapitola o fungování LLM. Takto natrénovaný LLM in odpovědích nedokáže rozlišit, který uživatel měl jaká práva na konkrétní firemní data, na základě kterých LLM odpoví. Pokud model zná odpověď, odpoví každému, kdo se správně zeptá. Tím se metoda trénování vlastního LLM stává pro většinu firem nepoužitelná, z vně je firemní know-how zabezpečeno dokonale, ale uvnitř firmy nijak, jakýkoliv zaměstnanec s přístupem k promptu LLM se automaticky dostane k jakýmkoliv informacím z celého firemního know-how.
Viz výše uvedený příklad manažera, který se táže na něco ke konkrétní smlouvě, naučené LLM nad firemním know-how manažerovi nejspíše odpoví správně. Ale pokud se na něco o této smlouvě a zákazníkovi zeptá jakýkoliv jiný zaměstnanec s přístupem k promptu LLM, i jemu LLM podá všechny informace které zná, aniž tento zaměstnanec měl právo do smluv firmy se zákazníky vidět.
RAG architektura
Implementace AI nad firemními daty, založená na RAG architektuře, je v současnosti nejpoužívanější metoda, jak AI na bázi LLM naučit pracovat s firemním know-how. U výše popsaných metod implementací AI are stručně nastíněny problémy, které jsou s nimi spojené. Využití RAG architektury téměř všechny tyto problémy řeší. Pod zkratkou RAG se skrývá:
- Retrieval, tzn. vyhledání informací, na jejichž základě má LLM odpovědět na dotaz či požadavek v promptu.
- Augmentation, neboli rozšíření, vyhledané informace se připojí do promptu s uživatelským dotazem/požadavkem včetně instrukcí, jak má LLM odpovídat jen na základě těchto připojených informací.
- Generation, tzn. generování, to už je klasické LLM generování odpovědi na základě promptu, rozšířeného o související informace z firemního know-how.
Vyhledávání v know-how firmy
Podstatné u RAG je to Retrieval, vyhledání informací ve firemním know-how. V RAG architektuře je toto hledání založené na embedding, jejichž podstata je vysvětlena v první kapitole v sekci Embeddingy.
Příprava embeddingů
Nejprve se ze všech textů představující firemní know-how nařežou menší části textu, tzv. chunky. Cílem je rozdělit firemní textové know-how na takové části, která půjde co nejlépe poskládat jako kontext dotazu uživatele v promptu LLM. Pokud by byl chunk příliš malý, např. jedno slovo, nebyl by v něm dostatečně obsažen význam. Pokud by byl chunk příliš velký, např. celá kapitola, byl by příliš rozsáhlý, s více tématy, špatně by se vyhledával dle významu a LLM by ho méně efektivně zpracovávalo. Jsou různé metody, jak text rozdělit na chunky, např.:
- prosté rozdělení na části textů s fixní délkou znaků
- pokročilejší dělení dle odstavců či podkapitol
- sofistikované metody, kde se konce a začátky témat v textu určují opět pomocí AI
- někdy se z chunků dělá hierarchická struktura, do LLM se posílá širší okolí chunku apod.
Obvykle se délka jednoho chunku pohybuje kolem 256 až 512 tokenů, které opět vysvětlujeme v první kapitole. Používají se různá vylepšení jako je mírné překryvy textu, každý chunk obsahuje na začátku 10-20% konce předchozího chunku, aby se neztratila souvislost. Nebo na začátek každého chunku se přiřazuje kontext celého dokumentu, z kterého pochází, něco jako např. „Tento odstavec pochází z pracovních instrukcí pro výrobní linku X“ či „Tento odstavec pochází ze smlouvy o X se zákazníkem Y“.
Z takto vytvořených chunků se vypočtou embeddingy pro RAG, popsané v první kapitole. Tyto embeddingy se uloží do vektorové databáze včetně originálních textů, ze kterých vznikly.
Vyhledání kontextu k promptu uživatele
Uživatel zadá v promptu svůj požadavek/dotaz. Z něj se buď udělá embedding, nebo se před tím zadaný prompt ještě zpracuje. Od jednoduchých metod, jako je vyčištění promptu od zbytečných slov, či generování embeddingu z každého slova, až po sofistikované metody s využitím AI, jako je generování variant formulací dotazu, extrakce témat z promptu uživatele, či generování fiktivních odpovědí, z kterých se teprve vytváří embeddingy. Jako výsledek zpracování promptu je jeden či několik embeddingů ze zadaného promptu uživatele. K tomuto výslednému jednomu či několika embeddingům se ve vektorové databázi s uloženými embeddingy z fáze přípravy vyhledají jim nejbližší embeddingy ve vektorovém prostoru. Ty nejspíše obsahují informace z firemního know-how, související s dotazem či požadavkem uživatele. U těchto vyhledaných embeddingů jsou ve vektorové databázi uloženy i originální texty, z kterých vznikly. Tyto originální texty se přidají do promptu jako kontext požadavku s instrukcemi, že LLM má odpovídat jen na jejich základě.
RAG architektura tedy udělá něco podobného, jako když uživatel při Využívání již hotových nástrojů AI bez napojení na firemní know-how do promptu připojí firemní dokumenty, dle kterých má LLM odpovědět. RAG to udělá sofistikovaněji. Když vezmeme výše vypsané Problémy s využíváním LLM bez napojení na firemní know-how, zde ve stejném pořadí platí:
- Na rozdíl od uživatele nejspíše RAG nalezne mnohem více sémanticky (významově) blízkých informací z firemního know-how, které souvisí s dotazem uživatele v promptu. LLM má tedy v promptu více souvisejících informací, na základě kterých může vygenerovat odpověď.
- Vyhledanými podklady RAG nejsou celé firemní dokumenty, ale jen jejich s dotazem související fragmenty. Takže se nejspíše všechny tyto texty vejdou do kontextového okna LLM.
- Protože texty obsahují jen z dokumentů vyřezané informace skutečně související s dotazem, LLM z nich může vytvořit odpověď, aniž se ztratí v detailu dlouhého textu z velké části nesouvisejícího s dotazem, viz funkce LLM.
Doplnění odpovědí o odkazy na zdroje
RAG architektura odstraňuje kritický nedostatek Tréninku a implementace interního LLM, kde LLM nedokáže v odpovědích uvádět odkazy na firemní dokumenty, z kterých čerpal informace pro odpověď. K embeddingům uložených ve vektorové databázi, lze jako metadata připojovat odkazy na zdrojové dokumenty, či dokonce jejich konkrétní části, z kterých byl ve fázi přípravy embedding vyroben. RAG dokáže tyto odkazy připojovat k odpovědím LLM, tazatel si může ověřit v originálním zdroji odpovědi, zda LLM nehalucinuje. Zabezpečení firemního know-how u RAG architektury bude probráno v samostatné podkapitole, RAG dokáže odstranit téměř všechny nevýhody v zabezpečení dat, jmenované u předchozích dvou metod implementace AI.
Použijeme-li dříve uvedený příklad, kde uživatel do svého promptu „Jak se na lince pro výrobu produktu X upíná produkt do mechanismu linky“ vloží firemní dokument s pracovními instrukcemi pro danou výrobní linku, RAG architektura toto udělá za uživatele sofistikovaněji. Popis „upínání“ bývá v dokumentaci často rozprostřen mezi textové návody více pracovních instrukcí, technické výkresy s popisky, kusovníky, mohou s ním souviset i informace v dokumentech o bezpečnosti práce apod. RAG při správně položeném dotazu vyhledá nejspíše většinu těchto textů, očištěných o informace s dotazem nesouvisející. Odpověď LLM na prompt obohacený o tyto texty bude přesnější a výstižnější. Díky od RAG připojených odkazů k odpovědi LLM na zdrojové texty může tazatel odpověď ověřit v odkazovaných dokumentech.
Podobně, když se manažer v promptu zeptá, zda u konkrétního zákazníka něco neporušuje jím popsanou činností v promptu, a pokud ano, jaké z toho plynou sankce, na rozdíl od tazatele, který k promptu přiložil celou smlouvu, RAG vyhledá nejen tuto smlouvu se zákazníkem a v ní jen pasáže související s dotazem, ale obdobné texty RAG možná najde, pokud existují, např. v přílohách smlouvy, v uložené komunikaci se zákazníkem o předmětu smlouvy, ve směrnicích specifikující obecná pravidla firmy pro práci se zákazníky apod. Odpověď LLM na dotaz bude opět výrazně lepší než jen s přiloženou smlouvou k promptu, s možností ověření v dotčených dokumentech, že to tak skutečně je.
Zabezpečení dat této metody
Uvnitř firmy
Při výrobě embeddingů z nařezaných textů know-how, popsané ve fázi jejich Přípravy, lze k embeddingům ukládat absurdní metadata, např. již zmíněné odkazy na zdrojové texty. Tato metadata lze využívat i k uložení a následnému určení práv tazatele na konkrétní texty, související s vyrobeným embeddingem. Existuje více metod, jak to dělat, např.:
- Filtrování dle metadat: Do metadat embeddingu se uloží informace, dle kterých budou ve vektorové databázi při hledání blízkých embeddingů k dotazu uživatele filtrovány jen embeddingy, na které má uživatel právo. Takovéto filtrování enginem vektorové databáze umožňuje efektivní a rychlé vyhledání blízkých embeddingů k embeddingu dotazu. Avšak neumožňuje komplexní řízení práv. K embeddingu se jako metadata ukládá např. seznam povolených uživatelů, skupina či role, kam musí uživatel patřit, a pod. Z toho je vidět, že takto nejde vybudovat komplexní, v čase se ve firmě měnící systém řízení práv.
- Řízení přístupů na základě vztahů: K embeddingu se uloží id objektu, z kterého byl embedding vygenerován. Při hledání blízkých embeddingů k dotazu uživatele vektorová databáze vrátí např. 50 nejbližších výsledků bez ohledu na práva. RAG architektura se zeptá externí služby, poskytující komplexní řízení práv ve firmě, které z těchto 50 konkrétních objektů má právo tazatel vidět. Do promptu LLM se přidají jen texty z embeddingů, na jejichž zdrojové objekty má uživatel právo. Pokud je takových embeddingů ve vyhledaných 50-ti málo, iteračně RAG vyhledává ve vektorové databázi jiné embeddingy např. s výběrem jiné metriky či prahové hodnoty, které možná nejsou dotazu uživatele tak „blízké“ jako předchozích 50 vyhledaných, ale uživatel má právo vidět objekty s texty spojenými.
Týmto způsobem lze z hlediska zabezpečení dat zaručit, že na rozdíl od natrénovaného LLM nad firemním know-how, LLM vrátí uživateli na jeho dotaz či požadavek pouze informace, na které má uživatel v rámci firemního know-how právo je vidět.
Vně firmy
RAG architekturu lze v případě potřeby obdobně jako u zabezpečení natrénovaného LLM nad firemním know-how plně uzavřít v intranetu firmy, a tak firemní know-how plně ochránit před jakýmkoliv únikem vně firmu. Pro tento případ je potřeba na firemních serverech vedle firemní platformy, v které je uloženo firemní know-how, provozovat také:
- Vektorovou databázi pro uložení embeddingů: Zde jsou k dispozici na trhu jak velká škálovatelná řešení s pokročilými funkcemi pro vyhledávání, např. vektorové DB Qdrant či Milvus, tak řešení jednodušší na nastavení a provoz, vhodná pro menší až střední projekty, jako např. ChromaDB
- Model pro výrobu embeddingů: Na trhu jsou špičkové modely např. od BAAI, které jsou multilinguální a tudíž vhodné i pro češtinu, nebo modely od výrobců jako jsou MixedBread.ai, Hugging Face či Nomic AI.
- Vlastní obecně naučené LLM: Na trhu jsou LLM od výrobců jako jsou Google, Meta, Alibaba Cloud, Mistral AI a dalších jak se špičkovým výkonem, které obvykle vyžadují výkonný hardware, více GPU s vysokou VRAM, tak jsou od těchto výrobců k dispozici modely méně náročné na hardware.
Takovýto obecně naučený LLM lze v tomto případě použití navíc pomocí Fine tuning dotrénovat např. na firemní styl komunikace, což je poměrně zajímavé rozšíření obecné funkce LLM.
Je třeba zvážit náklady takového řešení, u špičkových řešení půjde pořízení HW do milionů, nezanedbatelné částky půjdou i na provoz, kromě elektřiny a chlazení to budou zejména náklady na experty, kteří budou jmenované systémy udržovat a aktualizovat. Náklady na experty jsou často vyšší než samotný hardware a jeho provoz. Z toho důvodu k uzavření vektorové databáze, modelu pro výrobu embeddingů a LLM, do intranetu firmy se tedy obvykle přistupuje pouze v případech, kdy ochrana soukromí je naprosto kritickým požadavkem, či se počítá s masivním provozem AI, kde budou objemy nad 10 miliard tokenů měsíčně, v tomto případě to někdy dává i ekonomický smysl.
Většina firem si vystačí s provozem, kde k vektorové DB, modelu pro výrobu embeddingů a LLM přistupuje přes API k již hotovým řešením SaaS. Na trhu jsou vysoce kvalitní řešení od OpenAI, Azure OpenAI Service, Anthropic, DeepSeek (tady bude z hlediska zabezpečení v některých regionech, např. v EU problém, že servery jsou v Číně), Groq či Mistral AI. Existují univerzální adaptéry, jako např. LiteLLM., pomocí nichž se lze přepínat mezi jednotlivými řešeními a případně měnit SaaS dodavatele dle měnících se požadavků na zabezpečení, výkon a kvalitu, aniž musí firma měnit celý firemní systém. Dodavatelé SaaS řešení obvykle zaručují, že na posílaných datech přes API nebudou trénovat své LLM ani je jakkoliv jinak využívat, někteří dodavatelé zaručují provoz v datacentrech v EU, např. Azure OpenAI Service či Mistral AI. Náklady SaaS řešení se obvykle počítají z množství tokenů, které projdou přes API. Pokud nebude firma posílat přes API miliardy tokenů měsíčně, vyjde SaaS řešení mnohem ekonomičtěji než provozovat vše na svých serverech.
Agentický RAG
Zpracování požadavku v klasickém RAG
Výše popsaný RAG se obvykle označuje jako Klasický RAG. Zpracovává požadavek/dotaz uživatele následovně:
- Uživatel vznese požadavek/dotaz.
- Dojde k obohacení promptu s požadavkem/dotazem:
- Různými metodami výše popsanými v článku se vyhledají ve vektorové databázi embeddingy požadavku uživatele sémanticky (významově) nejbližší.
- Prompt pro LLM se složí z: požadavku uživatele, textů, z kterých byly vytvořeny vyhledané embeddingy, doprovodných instrukcí pro LLM, jak má na základě požadavku uživatele a připojených textů odpovědět.
Jako doprovodné instrukce se obvykle uvádí instrukce, jak využít připojené texty, např. „Odpovídej jen na základě informací připojených k dotazu.“, jakou osobnost (identitu) LLM reprezentuje a jaká je jeho role, např. „Jsi asistent Karel – asistent s umělou inteligencí zaměřený na plnění úkolů nad skladem s brzdovými součástkami.“, jakým stylem má LLM odpovídat, např. „Odpovídej přátelsky, jasně a ochotně.“, a různé další pokyny ovlivňující způsob odpovědí LLM, např. „Odpovědi by měly být stručné a praktické. Postupuj krok za krokem pouze tehdy, je-li to skutečně nutné (1–3 věty na krok). V případě potřeby pokládej vždy pouze JEDNU upřesňující otázku.“. LLM na základě obohaceného promptu vygeneruje odpověď. Mechanismus, jak ji generuje, je opět podrobně popsán výše v článku.
Limity klasického RAG
Takto klasicky pojatý RAG naráží na určité limity:
- ne všechny informace jsou vhodné k ukládání do vektorové databáze ve formě embeddingů a poté k vyhledávání dle blízkosti významu embeddingu k požadavku uživatele.
- Vhodné informace k uložení ve formě embeddingů bývají takové informace, které jsou v čase poměrně stabilní a mají silnou sémantickou (významovou) hodnotu. Typické informace z firemního know-how, vhodné k tvorbě embeddingů a jejich uložení ve vektorové databázi pro RAG zpracování jsou např. směrnice, pracovní postupy, smlouvy, obsah vzdělávacích kurzů, popisy procesů a pravidel, popisy výrobků firmy apod.
- Nevhodné informace k uložení ve formě embeddingů se naopak v čase často mění, někdy se mění i v kontextu jejich použití, obvykle nenesou výrazný sémantický význam, dle kterého by bylo vhodné vyhledávat vektorovou blízkost, tzn. podobnost. Např. u výše zmíněných výrobků firmy, jejichž popisy jsou uloženy ve formě embeddingů, se může jednat o počty jejich kusů na skladě. Tato informace se velmi rychle v čase pro každý výrobek mění, neustálé „přegenerovávání“ a ukládání embeddingů s počtem kusů nedává smysl. Vektorové hledání dle podobnosti pro počet kusů není efektivní, respektive nejspíše nebude fungovat vůbec.
U zmíněných vzdělávacích kurzů používaných ve firmě, jejichž popisy jsou uloženy ve formě embeddingů, přidělení konkrétních kurzů konkrétnímu uživateli nedává smysl do embeddingů ukládat, to by se muselo pro každého uživatele uložit ve zvláštním embeddingu seznam jemu přidělených kurzů, což by pro sémantické vyhledávání také nebylo vhodné. Navíc např. informace o splnění konkrétního kurzu pro konkrétního uživatele, která je asi také zajímavá pro LLM odpovědi, se v čase často mění, embeddingy s uložením seznamu kurzů přidělených uživateli by se opět musely neustále přegenerovávat. Ukládat informace tohoto typu do embeddingů, budeme jim říkat „živá data“, nedává smysl.
S těmito „živými daty“ klasický RAG neumí dobře pracovat, ale tazatel, jemuž má LLM s využitím RAG technologie odpovědět, by nejspíše chtěl znát odpovědi i na takovéto věci z firemního know-how.
- Ne všechny dotazy/požadavky lze splnit v jednoprůchodovém řešení dotaz-obohacení promptu-výstup LLM klasického RAGu. Někdy je potřeba na jeden dotaz uživatele podniknout více akcí (kroků) k jeho zodpovězení, např. vyhledat výrobky odpovídající popisu tazatele (najde se ve vektorové databázi), poté určit aktuální počty na skladě pro vyhledané výrobky (není ve vektorové databázi). Klasický RAG není navržen pro komplexní vícekrokové workflow a plánování, která jsou přirozenou součástí agentických systémů.
Rozšířené možnosti v Agentickém RAG
Existují pokročilejší metody, které se obvykle označují jako Agentický RAG, Hybridní RAG či řadou jiných názvů, např. Multi-source RAG, neexistuje zatím přesná terminologie ani shoda na přesné funkci. Zde si popíšeme technologii, které je nejbližší termín Agentický RAG. LLM zde funguje jako „mozek“ s jistou autonomií, v jejímž rámci si dokáže vytvořit plán řešení úlohy, rozdělí ji na dílčí kroky a následně rozhodnout, které Nástroje (Tools) použije pro splnění jednotlivých kroků. Poté vyhodnocuje výsledky a plánuje další kroky, dokud nesplní dotaz/požadavek uživatele.
Nástroje (Tools)
Jádrem Agentického RAGu are tzv. Nástroje (Tools). Nástroje dodávají LLM informace pro obohacení promptu obdobně jako výsledek vyhledání ve vektorové databázi klasického RAG, LLM dokáže tyto Nástroje sám volat dle svého rozhodnutí pro získání nějakého textu (informací) pro obohacení svého promptu. Každý Nástroj představuje vlastně nějakou externí (mimo LLM) programátorskou funkci, která vrací pro LLM nějaké informace. Pro Nástroje (Tools) jsou již v podstatě standardizovány, každý Nástroj má:
- Název: např. „Vyhledat_pocet_vyrobku_na_sklade“. Tento název je vlastně „spojnice“ mezi funkcí, která vrací požadovaná data a tím, co o této funkci „ví“ LLM. Z důvodu zabezpečení LLM nikdy neví, kde tato programátorská funkce leží v kódu, nezná její vnitřní logiku a neumí ji vyvolat. Když ji chce LLM vyvolat, jen předá „požadavek“ na vyvolání funkce s uvedeným Názvem a určí hodnoty parametrů (argumentů) funkce, samotné vyvolání funkce s argumenty dodanými od LLM probíhá mimo kontrolu LLM, v externím systému, v kterém je Agentický RAG implementovaný.
- Popis nástroje určený pro LLM: to je vlastně návod pro LLM, jak nástroj používat. Vysvětluje se v něm LLM, k čemu nástroj slouží, jaká jsou kritéria jeho spuštění, kdy ho spouštět a kdy naopak ne, jaká je podstata dat, která Nástroj vrací, jaký je jejich formát, jak se vyplňují parametry Nástroje, jak se chovat v případě chyby nástroje apod.
- Parametry: strukturovaný popis parametrů (argumentů) programátorské funkce spojené s nástrojem, tzn. co a jak se do parametrů funkce vkládá při vyvolání Nástroje. Např. u funkce vracející počet výrobků na skladě bude parametrem nejspíše identifikace výrobku, pro který se počet jeho kusů na skladě hledá.
Existují standardy pro popis nástrojů jako např. OpenAI Tool Calling (JSON Schema) či Model Context Protocol (MCP), který standardizuje komunikaci modelů s externími nástroji a zdroji dat. Pro pochopení základní funkce Agentického RAGu není třeba tyto standardy blíže znát.
Autonomie v řešení požadavků
Oproti klasickému RAG Agentický RAG přináší schopnost autonomního rozhodování, iterace, dekompozice, a tudíž řešení komplexních úloh. Klasický RAG funguje lineárně, vezme dotaz → vyhledá podklady → vygeneruje odpověď. Agentický RAG dokáže v průběhu řešení požadavku kontrolovat, zda nalezené podklady jsou dostatečné a pokud ne, iteračně s přeformulováním vyhledávacího dotazu získávat jiné podklady, dokáže získávat podklady nejen z vektorové databáze ale i z řady zdrojů „živých dat“, dokáže úkol dekomponovat na několik pod-úkolů, ty postupně vyřešit a tím se dostat k finálnímu řešení.
Pokud je požadavek uživatele zpracováván Agentickým RAGem, LLM je předán nejen textový požadavek uživatele, ale i seznam Nástrojů, které může LLM použít k zodpovězení požadavku. Moderní LLM dokáží seznam nástrojů přijmout ve speciálním parametru ve formátu nějakého výše jmenovaného standardu. LLM si poté analyzuje požadavek uživatele a Popisy poskytnutých nástrojů, dle toho se rozhodne, zda a který nástroj použít k vyřešení požadavku. LLM předá požadavek na použití konkrétního Nástroje (v požadavku uvede Název Nástroje a naplnění Parametrů) externímu systému v kterém svůj požadavek uživatel zada, externí systém vyvolá požadovanou funkci a její výstup předá LLM, LLM si o tento výstup z Nástroje obohatí prompt. Na základě takto obohaceného promptu se může LLM opět rozhodnout, že chce použít ještě nějaký další Nástroj a cyklus se opakuje až do chvíle, kdy LLM rozhodne, že již z promptu, který obsahuje informace dodané všemi použitými Nástroji, vygeneruje výstup.
Aby se LLM tímto způsobem „netočil“ neustále dokola a nevyžadoval stále nové a nové volání Nástrojů, lze nastavit pravidla, kdy už má LLM generovat finální výstup, a ne žádat další použití nějakého Nástroje. Tato pravidla jsou dána:
- Vnitřní logikou LLM: Moderní LLM s podporou volání Nástrojů jsou trénovány, aby rozpoznaly, že již obsah promptu má dostatek informací pro vygenerování odpovědi.
- Explicitními instrukcemi dodanými do promptu: tzn. které se specifikují ve výše uvedených „doprovodných instrukcí pro LLM“ pro nastavení Osobnosti a Stylu komunikace LLM, např. instrukcí "Jakmile máš dostatek informací pro spolehlivou odpověď, okamžitě odpověz uživateli a nevolej další nástroje.", či instrukcemi v Popisu nástroje, např. "Pokud tento nástroj dvakrát za sebou nevrátí žádný výsledek, nepokoušej se o další volání a přiznej uživateli, že informaci nemáš.".
- Nastavením limitů v produkčním prostředí: ve kterém je LLM voláno pro odpovědi uživatelům. Zde lze obvykle nastavit např. maximální počet vyvolání Nástrojů v jednom dotazu uživatele, maximální čas pro běh volání nástrojů a odpovědi na dotaz uživatele, jinak se celý proces ukončí apod.
V Agentickém RAGu se obvykle i hledání ve vektorové databázi (klasický RAG) poskytne jako Nástroj. Což samo o sobě výrazně zvyšuje přínos použití RAG technologie, i kdyby nebyly implementovány již žádné jiné Nástroje pro dodávání informací o „živých datech“. Přináší to do RAG technologie:
- Vícekrokové uvažování a dekompozici: Klasický RAG nezvládá požadavky, pokud odpověď vyžaduje syntézu informací ze více různých dokumentů. Např. u dotazu „jaký je celkový objem zakázek ve smlouvách se zákazníkem X“ si dokáže Agentický RAG tento požadavek rozložit na podúlohy, kde v prvním kroku najde smlouvy, kterých se požadavek týká, v druhém kroku z nich zjistí jednotlivé zasmluvněné částky a v třetím kroku je sečte a odpoví.
- Opakovaná sebekorekce: Agentický RAG umí zhodnotit kvalitu nalezených dat z vektorové databáze. Pokud vyhledávání významově blízkých embeddingů dotazu uživatele vrátí irelevantní texty, Agentický RAG se s tím nespokojí a neodpoví na jejich základě, ale dokáže přeformulovat požadavek uživatele na jehož základě se vyhledávalo ve vektorové databázi, a zkusí vyhledávat znovu. To může dokonce opakovat vícekrát, než nalezne nějaké skutečně relevantní texty pro odpověď.
Když se vrátíme k výše používanému příkladu výrobků na skladě, pokud je k dispozici Nástroj „Vyhledavani_RAG“ (hledá ve vektorové DB embeddingy blízké zadanému textu) a Nástroj „Vyhledat_pocet_vyrobku_na_sklade“ (vrátí počet konkrétních výrobků na skladě), když uživatel vznese dotaz „Které třmeny použitelné do brzdového systému Ford Escort máme na skladě“, Agentický RAG nejspíše (záleží na LLM) se pokusí nalézt v prvním kroku třmeny do specifikovaného brzdového systému Ford Escort, k čemuž použije Nástroj „Vyhledavani_RAG“ pro vyhledávání sémanticky blízkých textů ve vektorové databázi. Poté na všechny ve výsledku nalezené třmeny se pomocí nástroje „Vyhledat_pocet_vyrobku_na_sklade“ LLM iteračně zeptá, kolik je vždy konkrétních třmenů na skladě, a nakonec z takto obohaceného promptu vygeneruje LLM odpověď, do které zařadí jen ty třmeny, jejichž počet na skladě je větší jak nula, s uvedením konkrétního počtu konkrétních třmenů na skladě. Jak je vidět, to výrazně převyšuje možnosti klasického RAG.
Pokročilá řešení s Agentickým RAGem se umí vypořádat i se situací, když je Nástrojů k dispozici příliš, např. desítky či stovky. To se řeší v podstatě klasickým RAGem, kde Popisy Nástrojů, které jsou k dispozici, se také uloží ve formě embeddingů do vektorové databáze. Systém na základě dotazu uživatele vyhledá v první fázi klasickým RAG ve vektorové databázi jen menší množství „nejvhodnějších“ Nástrojů pro použití k vyřešení dotazu. Tyto vyhledané Nástroje předá systém poté v parametru LLM pro Nástroje a v druhé fázi se pak již pokračuje tak, jak je výše popsán Agentický RAG.
Měnění stavu „okolního světa“
Použití Nástrojů v Agentickém RAG přináší zcela novou funkcionalitu, kterou Klasický RAG nenabízí. Klasický RAG „jen sbírá“ informace z „okolního světa“ reprezentovaného uloženými informacemi o tomto světě v embeddingách vektorové databáze a na základě nalezených informací poskytne LLM odpověď tazateli. Nástroje v Agentickém RAGu mohou tento „okolní svět“ i měnit. Funkce spojená s Nástrojem, o její vyvolání požádá LLM externí systém zprostředkovávající Agentický RAG, může nejen vracet požadované informace pro odpověď LLM, ale může i provést „libovolné“ změny v systémech, na které je externí systém hostující Agentický RAG napojený. Je jen na tvůrcích Nástroje, jakou funkcionalitu Nástroji implementují. Takový Nástroj může např. posílat e-maily zákazníkům, registrovat uživatele na termíny kurzů, měnit počty výrobků na skladě, vystavovat faktury, v extrémním případě i odesílat peníze z účtu firmy dodavatelům, a provádět tisíce jiných myslitelných věcí. Ve spojení s výše popsanou schopností Agentického RAGu dekomponovat na něj vznesené požadavky na pod-úkoly a ty autonomně provádět je vidět, že možnosti jsou obrovské. S tím je spojené i vysoké bezpečnostní riziko, kterému se věnuje následující podkapitola.
Požadavky na zabezpečení v Agentickém RAG
Z hlediska zabezpečení firemního know-how vyšší autonomie agentických systémů přináší i nová rizika. Chybně navržený Nástroj nebo nedostatečně nastavená oprávnění k jeho použití mohou vést k tomu, že Agentický RAG získá přístup k informacím nebo funkcím, které neměl použít. Proto je důležité věnovat pozornost řízení oprávnění jednotlivých Nástrojů, auditování jejich použití a omezení rozsahu akcí, které může agent samostatně provádět.
Pokud použité Nástroje pouze vrací informace z externích systémů pomocí volání na Nástroje napojených funkcí v externích systémech, je nutné „pouze“ zabezpečit, aby tyto funkce byly volány s identitou přihlášeného uživatele pracujícího s Agentickým RAG, a uvnitř funkcí byla implementována bezpečnostní pravidla stejně jako v jiných funkcích externího systému. To se týká i případů, kdy s Agentickým RAG nepracuje konkrétní přihlášený uživatel, ale je spouštěn z nějakých např. naplánovaných procesů. I v tom případě musí být Agentický RAG spuštěný s nějakou identitou, se kterou jsou spojena práva v externích systémech, v nichž Agentický RAG volá prostřednictvím Nástrojů nějaké funkce. Např. ve funkci externího systému, která vrací počet výrobků na skladě, musí být nejprve ošetřeno, že uživatel, pod kterým je tato funkce volána, tzn. jehož identita byla funkci zabezpečeně předána z hostitelského systému Agentického RAG, má právo vidět počty výrobků na skladě. Takové právo může být vázáno i na konkrétní výrobky. Pokud uživatel, pod kterým je funkce vyvolána, toto právo nemá, funkce do promptu LLM prostřednictvím Nástroje vrátí pouze informaci typu “Na požadovaná data nemáte oprávnění“.
Výstup LLM na požadavek uživatele, jak je popsáno výše u klasického RAG, obsahuje odkazy na podklady, které LLM použil k odpovědi. Je tedy na koncovém uživateli (tazateli), aby si z podkladů ověřil, zda LLM nehalucinuje. I Nástroje mohou vracet odkazy na zdroje podkladů, které použily k obohacení promptu LLM. Např. funkce vracející počet výrobků na skladě může vrátit kromě zjištěného počtu výrobků na skladě i odkaz do externího systému, na kterém lze přímo v tomto systému ověřit skutečný počet jmenovaných výrobků na skladě. Je-li implementovaná funkcionalita Single Sign-On, uživatel si může tuto informaci lehce ověřit pouhým kliknutím na odkaz.
Zcela jiná situace nastává u Nástrojů, které dokáží externí systém i měnit, provádět v něm různé akce. Je nutné si uvědomit, že Agenti (Agentický RAG) nemají žádnou právní subjektivitu, a tudíž za jím provedené akce bude zodpovědná vaše firma. Je proto třeba dodržovat kromě výše jmenované nutnosti aplikovat uvnitř funkcí spojených s Nástroji práva dle identity uživatele i následující pravidla:
- Důsledně v Popisu Nástroje specifikovat kritéria jeho spuštění a jeho účel. Např. pokud Nástroj slouží k přihlášení studenta na kurz, nestačí specifikovat ve formě „Přihlásí studenta na kurz“, ale je v Popisu pro LLM potřeba uvést i něco na způsob "POUŽIJ POUZE v případě, že uživatel EXPLICITNĚ vyjádřil přání zaregistrovat se nebo přihlásit na konkrétní termín kurzu (např. 'Zapiš mě', 'Chci se přihlásit'). NIKDY nevolej tento nástroj, pokud se uživatel na kurz pouze ptá nebo zjišťuje volná místa.“.
- Obdobně důsledně je nutné popisovat i parametry Nástroje. LLM má tendenci si chybějící parametry domyslet z kontextu nebo historie, což je zde nebezpečné. Např. ve zmíněném příkladu registrace na kurz, kde asi jedním z parametrů bude identifikace kurzu, do popisu tohoto parametru např. uvést „"Unikátní ID kurzu. Pokud ho uživatel neřekl, NIKDY si ho nedomýšlej ani neodhaduj, napřed se ho zeptej nebo ho dohledej pomocí vyhledávacích nástrojů a v tom případě se opětovně ujisti, že to je kurz, na který se chce uživatel registrovat".
- Dle posouzení možných rizik vyvolání Nástroje implementovat Human-in-the-loop strategii, překládanou obvykle jako „člověk v rozhodovacím procesu“. V této strategii Agent akci neprovede, ale připraví ji tak, že vygeneruje např. odkaz do externího systému, na kterém musí uživatel akci provést/schválit. Např. i když uživatel požaduje, ať ho Agent zaregistruje na konkrétní kurz, výsledkem nebude registrace uživatele na kurz Agentem, ale Agentický RAG uživateli vygeneruje odkaz a požádá ho, ať svoji registraci finálně potvrdí na dodaném odkazu. Na připojeném odkazu se uživateli objeví v externím systému jeho konkrétně vyplněná přihláška na konkrétní kurz s tlačítkem „Registrovat“, či něco podobného, záleží jak jsou přihlášky implementovány v externím systému. Registrační tlačítko musí stisknout sám uživatel a ve formuláři si může finálně ověřit, že na “toto“ se chce skutečně zaregistrovat, případně si přečíst jaké podmínky a důsledky registrace má apod. Strategii „člověk v rozhodovacím procesu“ je doporučeno aplikovat v podstatě na všechny Nástroje, které mění data v externích systémech či v nich vyvolávají jakékoliv akce.
I když budete mít dobře popsané Nástroje pro LLM, tzn. kdy a jak je volat a jak používat jejich parametry, a uživatel ve svém požadavku na Agentický RAG správně a dostatečně specifikuje, co přesně chce od Agenta udělat, vždy je třeba mít na mysli, že tím Agentem je LLM pracující dle principů popsaných v kapitole Fungování AI na bázi LLM. Riziko halucinací, které zde mohou vést k nesprávnému volání Nástrojů, neklesne nikdy na nulu z podstaty fungování LLM, kde halucinace nejsou chybou, ale vedlejším efektem principu funkčnosti neuronové sítě LLM.
Ukázka implementace AI s RAG v platformě iTutor
Implementace klasického RAG AI nad firemním know-how v iTutor
iTutor je platforma, která mimo jiné:
- shromažďuje a organizuje firemní know-how
- řídí, které části know-how jsou přístupné kterým zaměstnancům s využitím kompetenčních či kvalifikačních matic, map vzdělávání a komplexního systému řízení práv
- poskytuje zaměstnancům informace, vzdělávání a podporu pro efektivní používání jimi sdíleného firemního know-how ve své každodenní práci
- umožňuje ověřovat pomocí automatického testování, 360-zpětné vazby, měření plnění cílů a dalších technik, že firemní know-how je správně uloženo, předáváno a účinně pomáhá v pracovním procesu každému zaměstnanci.
Platforma iTutor toho umí mnohem více, viz popis platformy iTutor, z hlediska v článku diskutované implementace AI nad firemním know-how takto stručný popis iTutor stačí.
Firemní know-how je v iTutor:
- centralizováno ve výkonném systému pro správu dokumentů (DMS) iTutor Documents, ve formě textových, obrazových, audio a video dokumentů. iTutor Documents je unikátní pro správu firemního know-how pro všechny typy firem od malých firem až po nadnárodní koncerny s multi-jazyčným prostředí, protože:
- má pokročilé workflow schvalování a připomínkování vznikajících verzí dokumentů s komplexní správou přístupových práv k verzím dokumentů.
- umožňuje vytvářet jazykové sub-verze dokumentů s vlastním schvalovacím workflow pro překladatele a schvalovatele jazykových mutací, podporuje obsahové odchylky a varianty verzí dokumentů, odpovídající konkrétnímu národnímu prostředí, zvykům a legislativě.
- má vestavěné business-pluginy pro specifické způsoby ukládání know-how, např. editor pracovních instrukcí, v kterém lze graficky vytvářet modulární interaktivní pracovní instrukce pro práci zaměstnanců na výrobních linkách či v jiných pracovních procesech.
- část firemního know-how je uloženo v iTutor LMS/LXP:
- část tohoto know-how je uložena ve formě popisu používaných kurzů ve firmě a vzdělávacího obsahu uloženého v e-learningových kurzech. Obsah těchto kurzů se týká zejména znalostí a dovedností, které je potřeba didakticky na vysoké úrovni předat zaměstnancům a on-line si ověřovat zpětnou vazbou pochopení obsahu. V iTutor je integrovaný nástroj třídy LCMS iTutor Publisher pro vývoj pokročilých e-kurzů a následné zpracování jejich obsahu pro AI. Obsah e-kurzů je obvykle „zabalen“ v různých interaktivních výukových strategiích a není snadno přístupný pro AI. Text know-how je v e-kurzech „ukryt“ v různých JS funkcionalitách, simulacích a interaktivních prvcích, k takovému obsahu se lze dostat jen sofistikovanou interakcí studenta s e-kurzem. iTutor Publisher dokáže z takovýchto interaktivních multimediálních e-kurzů vytvářet jejich textové obrazy, s převedením i skrytého obsahu do textově srozumitelné formy pro AI. Popisy všech používaných kurzů ve firmě včetně např. příloh obsahujících vyučovanou látku a obsah e-learningových kurzů jsou klasickou ukázkou firemního know-how vhodného na převedení do formy embeddingů a uložení do vektorové databáze metodou klasického RAG.
- část tohoto know-how leží ve formě „živých dat“ v různých datových strukturách iTutor LMS/LXP. Viz Limity klasického RAG, jedná se např. o informace ohledně plnění konkrétních kurzů konkrétními uživateli a jejich aktivitách v lekcích, informace o získaných certifikátech konkrétními uživateli, o vypsaných termínech kurzů a jejich vlastnostech jako jsou kapacity, ceny, přihlášení uživatelé, o schvalovacích procesech, kdo komu schválil, zamítl přihlášky a pod. Na tyto informace má k dispozici Agentický RAG v iTutor AI řadu Nástrojů, které může používat k získání konkrétních informací, viz Rozšířené možnosti Agentického RAG, jak funguje práce s těmito informacemi je popsáno v Agentický RAG v iTutor.
Koho blíže zajímá, jak se v integrovaných systémech DMS/LMS/LCMS/LXP spravuje firemní know-how, může si přečíst podrobnější článek zde. Nad firemním know-how spravovaným v platformě iTutor pracuje modul iTutor AI. Uživatel si může vybrat, zda chce pracovat v módu klasického RAG pouze nad informacemi uloženými ve vektorové databázi embeddingů, pro to je implementován klasický chatbot s RAG architekturou, či zda chce pracovat v módu Agentického RAG, na to je implementován AI Asistent popsaný v Agentický RAG v iTutor.
Klasický RAG v chatbotu aplikace iTutor Dokumenty funguje takto:
- Každý z dokumentů i e-kurzů v iTutor lze označit jako nepřístupný pro AI. Tím lze zabránit úniku extrémně citlivých dat např. z pohledu GDPR.
- Na pozadí iTutor pracuje iTutor know-how change agent. Ten detekuje veškeré změny v know-how spravovaném v iTutor. Byla-li vydána např. nová verze dokumentu v iTutor Documents, tento agent změnu zachytí a předá o ní informaci dalšími agentovi, iTutor RAG Creatoru.
- iTutor RAG creator je agent také běžící na pozadí iTutor. Dokáže z každého know-how uloženého v iTutor vytvořit embeddingy pro RAG s použitím pokročilých metod popsaných v sekci Příprava. Vytvořené embeddingy ukládá do vektorové databáze Qdrant, která je součástí iTutor. iTutor RAG creator ukládá do vektorové databáze ke každému embeddingu odkaz na objekt, ze kterého byl vytvořen. To umožňuje komplexně řídit práva na základě vztahů, jak je popsáno v zabezpečení dat Uvnitř firmy.
- Obvykle se firmě nepodaří soustředit veškeré své know-how v jediném systému, zde iTutor. Know-how firmy je často kromě systému s AI funkcionalitou rozprostřeno v řadě dalších systémů, jako jsou relační databáze, např. MS SQL Server, systémy pro správu projektů, např. Jira, kolaborační platformy, např. MS SharePoint, CRM systémy, např. SalesForce, komunikační kanály, např. Slack, systémy zákaznické podpory, např. Zendesk, či ERP systémy, např. SAP. iTutor RAG creator má vlastní API konektor, pomocí kterého ho lze snadno propojit s téměř jakýmkoliv externím systémem, v kterém je uložena nějaká část know-how firmy. Tak lze do RAG vektorové databáze v iTutor zrcadlit firemní know-how ve formě embeddingů vytvořených iTutor RAG creatorem z libovolného jiného firemního zdroje.
- Když uživatel v iTutor AI zadá požadavek či dotaz, který chce zpracovat pomocí AI, zpracování proběhne dle principů podrobně popsaných výše v metodě RAG architektura:
- Z dotazu uživatele iTutor AI vyrobí embedding pomocí extrakce témat z dotazu, viz Vyhledání kontextu k promptu uživatele.
- Ve vektorové databázi jsou vyhledány embeddingy blízké vyrobenému embeddingu z dotazu, nalezené embeddingy obsahují tudíž know-how související s dotazem.
- Na základě aplikace pokročilého řízení přístupů na základě vztahů jsou vybrány jen ty nalezené embeddingy, na které má tazatel právo.
- Prompt LLM používaného v iTutor AI je finálně tvořen textem dotazu uživatele, který je obohacen texty vyhledaných embeddingů obsahující know-how související s dotazem, a do promptu jsou přidány instrukce, jak s těmito texty má LLM pracovat. Zjednodušeně, že LLM má odpovídat na základě nalezených textů z embeddingů a ne na základě svých obecných znalostí.
- V nastavení iTutor AI lze určit, jaký model LLM je používán, či jak se určuje blízkost embeddingů im vektorové databázi.
- Uživatel dostane odpověď od iTutor AI, což je odpověď použitého LLM, doplněná technologií RAG o odkazy na použité dokumenty, e-kurzy v iTutor, nebo objekty z externích systémů, v kterých si může ověřit správnost odpovědi AI, viz Doplnění odpovědí o odkazy na zdroje.
- V iTutor AI je implementován monitorovací systém, pomocí kterého mohou administrátoři analyzovat odpovědi AI a hodnocení těchto odpovědí od tazatelů. Na základě toho lze funkčnost iTutor AI i uložené podklady know-how opitmalizovat.
- iTutor AI umožňuje svoji funkčnost „vytáhnout“ vně platformy iTutor. Zákazníci si mohou vytvářet na bázi iTutor AI své vlastní AI chatboty, určovat pro každého takového AI chatbota, na jaká data firemního know-how má právo a upravovat jeho design. Takovýto zákazníkem vytvořený AI chatbot mohou zákazníci umísťovat do svého intranetu či na své internetové stránky. Na firemních stránkách Kontis si můžete prohlédnout jednoho takového AI chatbota, vytvořeného v iTutor AI, pracujícího nad informacemi určenými v iTutor AI pro potenciální zákazníky Kontis. Platforma iTutor nativně podporuje řadu standardů pro Single Sign-On (SSO), včetně integrovaného ověřování vůči Active Directory a moderních protokolů SAML 2.0 či WS-Federation. To umožňuje hladkou integraci s IdP platformami jako MS Entra ID, AD FS, Okta apod. Má-li zákazník implementováno Single Sign-On, může chatbot vytvořený v iTutor AI a umístěný v intranetu zákazníka odpovídat zaměstnanci na základě jeho oprávnění k přístupu ke konkrétnímu know-how firmy.
- Existuje i samostatný produkt iTutor Chatbot odvozený z iTutor AI, v kterém si může kdokoliv snadno během pár minut vytvořit vlastního AI chatbota, metodou drag& drop do něj vhodit soubory a webové stránky, na jejichž základě chatbot odpovídá. Takového chatbota pak lze provozovat na svých webových stránkách. iTutor Chatbota si můžete zkusit udělat na webu ai.itutor.eu. Zde si vyzkoušíte nejen to, jak LLM s RAG architekturou dokáže odpovídat na vaše dotazy na základě zpřístupněného know-how, ale případně můžete vytvořeného chatbota komerčně používat na svých stránkách k jakémukoliv účelu.
Schématický diagram fungování klasického RAG v iTutor
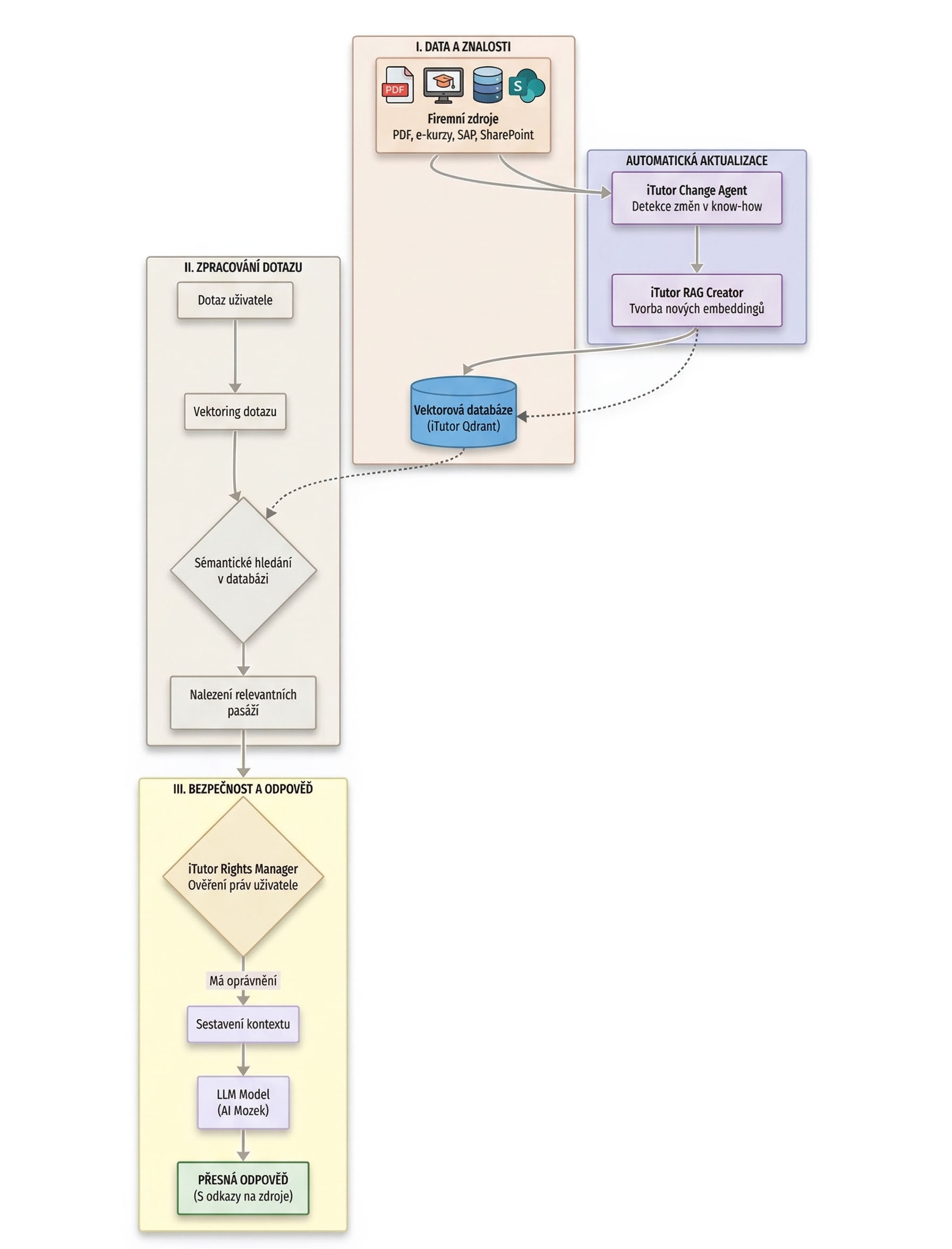
Agentický RAG v iTutor
V iTutor je k dispozici pokročilý Agentický RAG, jehož funkci zprostředkovává tzv. AI Asistent, který je dostupný v aplikacích iTutor určených pro koncové uživatele (profil Uživatel).
AI Asistent je agent, který má k dispozici řadu Nástrojů pro řešení komplexních úloh v platformě iTutor.
- Ve formě Nástroje má AI Agent zpřístupněné klasické RAG vyhledání ve vektorové databázi iTutor popsané v Implementace klasického RAG AI nad firemním know-how.
- AI Asistent má implementovánu řadu Nástrojů pro čtení „živých dat“ z platformy iTutor, jako jsou data o plnění konkrétních kurzů konkrétními uživateli, informace o aktivitách konkrétních uživatelů v lekcích kurzů, informace o získaných certifikátech konkrétními uživateli, data o vypsaných termínech konkrétních kurzů a vlastnostech těchto vypsaných termínů, např. jejich kapacity, ceny, přihlášení uživatelé na termín, místa konání termínu apod. AI Asistent má k dispozici Nástroje pro získávání dat o konkrétních probíhajících a proběhlých schvalovacích procesech, kdo komu co schválil, zamítl přihlášky a řadu dalších Nástrojů pro získávání dat z platformy iTutor.
- Do AI asistenta lze implementovat Nástroje pro změnu „živých dat“ v platformě iTutor, jako např. registrace uživatelů na kurzy, blíže popsané v podkapitole Měnění stavu „okolního světa“. Takovéto Nástroje se implementují vždy pro konkrétního zákazníka v pro něj adekvátní podobě z bezpečnostních důvodů, podrobně vysvětlených v podkapitole Požadavky na zabezpečení v Agentickém RAG.
- iTutor AI modul aplikuje pro poskytnutí Nástrojů do Agentického RAG jednu z nejlepších současně známých strategií spočívající ve filtrování Nástrojů na základě uživatelských práv ještě předtím, než Nástroje předá LLM k řešení požadavku. Tento přístup, často označovaný jako RBAC (Role-Based Access Control) for Tools, je založen na tom, že každý Nástroj definovaný v iTutor AI je spojen s množinou konkrétních práv z komplexního systému práv iTutor. Např. pokud Nástroj Vratit_seznam_clenu_skupiny vrací seznam uživatelů v nějaké Skupině uživatelů iTutor, pro získání seznamu členů skupiny je třeba mít v iTutor buď právo „ViewGroup“ na konkrétní skupinu, či musí být uživatel volající funkci spojenou s Nástrojem manažer konkrétní skupiny. S těmito právy je Nástroj Vratit_seznam_clenu_skupiny spojen. iTutor AI před předáním tohoto Nástroje do Agentického RAG nejprve zkontroluje, zda přihlášený uživatel má alespoň jedno z jmenovaných práv. To sice nezaručuje, že uživateli LLM použitím Nástroje vrátí seznam požadovaných uživatelů pro konkrétní uživatelem požadovanou skupinu, protože uživatel nemusí mít právo na tuto konkrétní skupinu či nemusí být jejím manažerem. Ale pokud nemá přihlášený uživatel ani jedno z jmenovaných práv na žádnou Skupinu uživatelů, je jisté, že mu tento Nástroj nebude k ničemu a iTutor AI tento nástroj do LLM pro řešení požadavku uživatele vůbec nepředá.
To v praxi přináší:- Vyšší bezpečnost: LLM se o existenci tohoto nástroje pro tohoto uživatele vůbec nedozví. Nemůže dojít k situaci, kdy by uživatel pomocí „prompt injection“ (podvržení instrukcí) přemluvil LLM k vykonání neoprávněné akce. Ta by tedy stejně měla být zachycena a „zahozena“ uvnitř funkce spojené s Nástrojem díky výše popsanému řízení práv uvnitř funkcí nástrojů.
- Ušetření kontextového okna: Neplatíte provozovateli LLM za zbytečné textové popisy toolů, které uživatel stejně nemůže použít.
- Vyšší přesnost: Čím méně Nástrojů se modelu nabídne, tím menší je šance, že si vybere nesprávný (tzv. halucinace nástroje).
AI asistent dokáže řešit požadavky a úkoly zadané uživateli, které vyžadují plánování, syntézu, dekompozici úkolu na kroky, získávání jak stabilních, tak „živých dat“ z know-how firmy. Jak to dělá, je podrobně popsané v kapitole Agentický RAG.
Zeptá-li se uživatel např. na nějakou oblast, ve které by se potřeboval dovzdělat, AI Asistent mu je schopen nejen najít kurzy, které jsou k dispozici pro tuto oblast, případně udělat stručnou syntézu z jejich obsahu, ale dokáže mu i podat informace, zda některé z těchto kurzů již neabsolvoval a nemá k nim certifikát, které z těchto kurzů má „rozstudované“ a v jaké fázi, ke kterým kurzům jsou vypsané termíny, které z vypsaných termínů mají volnou kapacitu apod. Ke všem poskytnutým informacím dokáže AI Asistent dodat odkazy, kde se může uživatel přímo na vypsaný termín přihlásit, kde může pokračovat v „rozstudovaném“ kurzu další nedokončenou lekcí, podá mu informace proč nemůže nějakou lekci spustit např. z důvodu nesplnění podmíken kladených na lekci, a které konkrétní podmínky uživatel nesplnil, jak je splnit atd.
Příklady využití
Na závěr se vrátíme k výše citovaným příkladům využití AI u zákazníka:
- Řada výrobních firem spravuje své know-how v iTutor, příklady z automotive si můžete prohlédnout zde. Know-how takové firmy bývá uloženo v iTutor Documents, kde jsou spravovány např. dokumenty s výrobními postupy, pracovní instrukce, směrnice, smlouvy. V kurzech iTutor LMS mohou být související informace obsažené např. v kurzech o Bezpečnosti práce. V externích systémech, jako je např. SAP, bývají spravovány jednak stabilní části know-how jako kusovníky výrobků s jejich popisy, jednak „živá data“ jako např. kolik konkrétních výrobků je na skladě, která výrobní linka má které pracovní místa neobsazená. Samotná platforma iTutor má k dispozici také řadu dalších „živých dat“, např. konkrétní popis výrobních linek s pracovními místy, dokáže určit kdo může na kterém konkrétním pracovním místě výrobní linky pracovat na základě aktuálního plnění svých kvalifikací.
Pokud se uživatel s takto organizovaným know-how v iTutor AI zeptá „Jak se na lince pro kompletaci výrobku X upíná výrobek do mechanismu linky a kde výrobek naleznu“, iTutor AI nejspíše nalezne většinu souvisejících textů ze všech jmenovaných zdrojů, zejména pokud je iTutor pomocí iTutor AI API konektoru napojen na kusovníky v SAP s popisy výrobků a byly implementovány Nástroje pro získávání informací o výrobcích na skladě (Nástroj čerpající data z externího systému SAP) a Nástroje pro získávání informací o přidělených a splněných kvalifikací (Nástroj čerpající data z platformy iTutor). Odpověď iTutor AI na dotaz bude proto nejspíše dostatečně přesná a výstižná, AI Asistent nejen odpoví, jak se konkrétní výrobek upíná do mechanismu linky, ale doplní i kde na skladě v počtu kolika kusů je výrobek dostupný a zda to může či nemůže tazatel udělat díky aktuálnímu stavu splnění jeho kvalifikací. Tazatel např. nemá splněnou kvalifikaci pro práci na pracovním místě výrobní linky, kde se výrobek upíná, všechny tyto informace si umí iTutor AI Asistent dohledat díky implementovanému Agentickému RAG. AI Asistent připojí ve své odpovědi odkazy na zdrojové podklady, tazatel si může odpověď ověřit přímo v odkazovaných podkladech.
- Pokud se manažer iTutor AI zeptá, zda u konkrétního zákazníka něco neporušuje jím popsanou činností v promptu, a pokud ano, jaké z toho plynou sankce, iTutor AI nejspíše vyhledá nejen smlouvu se zákazníkem a v ní pasáže související s dotazem, ale najde, pokud existují, i související texty např. v přílohách smlouvy. To vše může být uloženo v iTutor Documents, nebo v nějakém externím systému napojeném přes iTutor AI API konektor. Dále iTutor AI může vyhledat komunikaci se zákazníkem o předmětu smlouvy, pokud tuto komunikaci má firma uloženou např. v MS Exchange a bylo realizováno propojení Microsoft Graph API s iTutor AI API konektorem. iTutor AI ověří, zda tazatel má na nalezené informace týkající se smluv a komunikace se zákazníkem právo. Pokud ano, dá tazateli pravděpodobně velmi podrobnou a konkrétní odpověď. Pokud tazatel na takéto informace právo nemá, pokusí se iTutor AI vyhledat nějaké vzdáleněji související informace s dotazem. Např. nalezne ve směrnicích uložených v iTutor Documents obecná pravidla firmy pro práci a komunikaci se zákazníky. Poté odpoví alespoň dle těchto informací. Tazatel si může ověřit v použitých zdrojích, které iTutor AI přidá na konec odpovědi, že LLM nehalucinuje.
- Viz výše popsaná možnost vytvářet a „vytahovat“ AI chatboty vně platformu iTutor, pokud má zákazník v iTutor implementované Single Sign-On, může si např. vytvořit AI chatbota reprezentujícího pracovníka HR a tohoto chatbota umístit do intranetu firmy. Tento HR AI chatbot bude schopen odpovídat zaměstnancům jejich dotazy na HR oddělení firmy na základě informací, na které má konkrétní zaměstnanec právo plus na základě všem zaměstnancům přístupného know-how firmy o HR. Zeptá-li se např. zaměstnanec tohoto HR AI Chatbota na něco související s jeho pracovní smlouvou, chatbot mu bude nejspíše schopen přesně odpovědět, protože tento zaměstnanec má oprávnění ke čtení své pracovní smlouvy, a tudíž i HR AI chatbot, kterého se zaměstnanec ptá, bude mít přístup k informacím k jeho pracovní smlouvě. Obdobně bude HR AI Chatbot odpovídat jeho manažerovi s přístupem ke smlouvám podřízených. Zeptá-li se jiný zaměstnanec na pracovní smlouvu kolegy, žádné konkrétní informace od HR AI Chatbota nedostane.
Stručně shrnuto, iTutor je v oblasti AI platforma, která má plně implementovanou RAG architekturu včetně Agentického RAG a je schopna spravovat a AI zpracovávat veškeré firemní know-how. Navíc je platforma iTutor schopna zpracovat svým AI know-how uložené v řadě dalších systémů zákazníka a řešit zadané úkoly pomocí Agentického RAG s využitím plánování, rozdělení na kroky, syntézy a získávání „živých dat“ z různých systémů zákazníka. S poměrně nízkými náklady tak lze pomocí platformy iTutor implementovat používání AI nad veškerým know-how firmy. Řešení iTutor pro AI zpracování firemního know-how lze spustit ihned, pokud je celé firemní know-how uloženo v iTutor Documents a e-kurzech v iTutor LMS. Pokud je část know-how spravována „mimo“ platformu iTutor, je potřeba pouze implementovat jednoduché API konektory a Nástroje na tyto externí zdroje, kde je uloženo know-how a „živá data“. Náklady na experty při implementaci AI ve firmě jsou často vyšší než na HW a provoz technického řešení, hotová platforma iTutor tyto náklady minimalizuje.